© 2026 | All Right Revered.
Understanding the intricate process and core concept of data collection for machine learning requires a grasp of fundamental elements. Read our detailed blog to expand your knowledge.

Chief Technology Officer
A tech builder, mastering engineering processes and venture building by creating rapid, scalable, and solid product solutions. A staunch advocate for the disruptive capabilities of AI Co-Pilots in the software service industry.
The initiation of machine learning heavily relies on the availability of data. Data collection for machine learning, therefore, serves as a crucial preliminary step. Its purpose lies in gathering pertinent data aligned with the specific objectives of the AI project at hand.
Subsequently, this collected dataset forms the cornerstone that is prepared for the intricate process of training and integration into the machine learning model. Despite its seemingly straightforward nature, data collection embodies the primary and essential phase within the complex data processing continuum of the machine learning lifecycle. Furthermore, it plays a direct and significant role in shaping the performance and ultimate outcomes of the machine learning model.
Let’s proceed to discuss each aspect methodically.
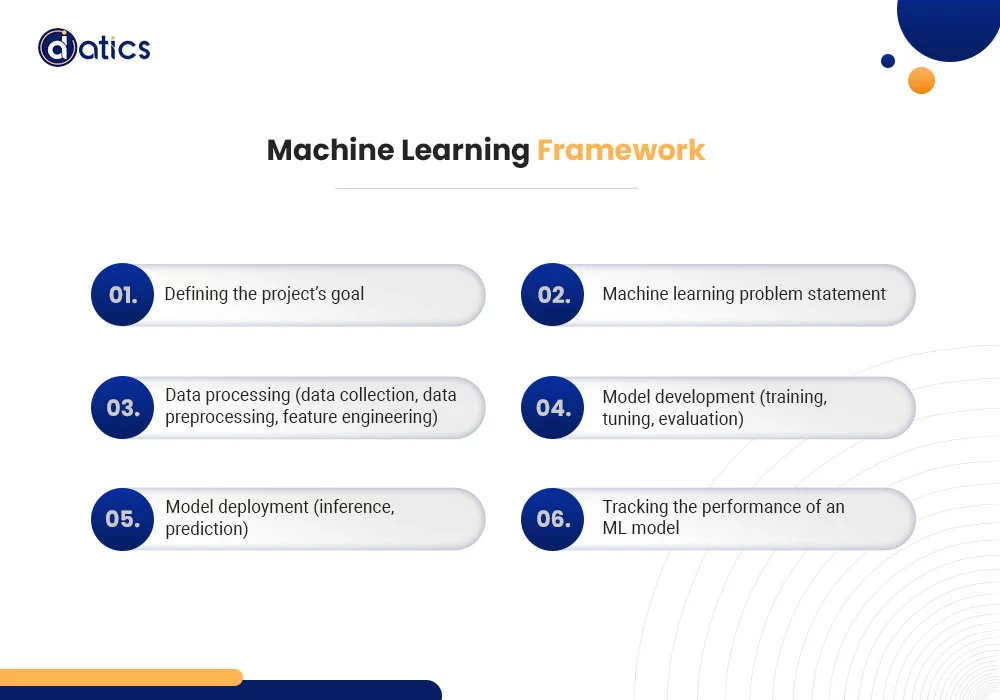
Machine learning involves understanding how data collection fits into the overall process. This framework encompasses:
Inefficient data collection presents a huge barrier to effective machine learning. This has spurred widespread discussions within the global tech community for two primary reasons.
First, the increasing adoption of machine learning has led to the exploration of new applications. These applications often lack sufficient labeled data, emphasizing the importance of efficient data collection methods.
Second, unlike traditional ML methods, deep learning algorithms can produce features on their own. This eliminates the need for extensive feature engineering, though it may require more annotated data to function properly.
However, the accuracy of the predictions or recommendations generated by ML systems relies heavily on the quality of the training data. Several issues might arise during ML data collection, significantly impacting the accuracy rate:

Bias: Human involvement in constructing ML models can introduce biases, making it challenging to prevent or eliminate data bias.
Incorrect data: The collected data may not align with the intended purpose of the ML problem statement, leading to inaccuracies in the final predictions.
Lack of data: Instances of missing data, such as empty values in columns or absent images, can pose challenges for specific prediction tasks.
Data disparity: Some groups or categories within the data might be underrepresented due to an unequal distribution of corresponding samples, impacting the model’s performance.
To produce a high-quality dataset and obtain thorough understanding of the field of machine learning, it is essential to learn about data collection tools and techniques. A solid foundation of quality data ensures success in any ML task.
With that in mind, let’s delve straight into the intricacies of data collection!
Recalling the fundamental principle in machine learning—garbage in, garbage out—underlines the critical role of high-quality data. Regardless of the sophistication of the model, the expertise of the data scientist, or the project’s budget, feeding poor-quality data yields subpar results.
Just as a sturdy foundation is vital for constructing a building, robust and reliable data serves as the cornerstone for developing effective machine learning models. This reliance on quality data has propelled the practical application of machine learning. It has facilitated the creation of sophisticated recommendation systems, predictive analytics, pattern recognition technologies, audio-to-text transcription tools, and even self-driving vehicles.
Statistics indicate that unstructured text data remains a primary focus, with 68% of AI developers utilizing it. Tabular data is also widely used, accounting for 59% of data utilization.

The data collection phase involves several key actions, including:

Labeled data serves as the processed raw data enriched with meaningful tags, enabling models to learn from it. When such information is absent, manual or automatic labeling requires significant effort.
Labeled data provides the necessary context for the machine learning algorithm to learn and make predictions. The labels serve as the ground truth or reference points that the model uses to associate input features with specific outcomes.
For example, in a supervised learning scenario, where the algorithm is trained on labeled data, each data point includes both input features and the corresponding label. The model learns patterns and relationships between the input features and the assigned labels during the training process. Once trained, the model can use this knowledge to make predictions on new, unlabeled data.
Labeling is a crucial step in preparing data for machine learning tasks, and the quality and accuracy of the labeled data significantly impact the performance of the machine learning model. It can be done manually by human annotators or automatically using algorithms, depending on the nature of the data and the task at hand.
Integrating and consolidating data from various sources constitutes a vital aspect of data collection in the realm of AI.
Ingesting refers to the initial phase of the data collection process. It involves actively gathering raw data from diverse sources, which can include databases, APIs (Application Programming Interfaces), external files, or any repositories where relevant information resides. This step is akin to casting a wide net to capture all potential data points that might contribute to the machine learning task at hand. The ingesting process aims to compile a comprehensive set of data that is pertinent to the objectives of the machine learning project.
After the data is ingested, the subsequent step is aggregation. This phase focuses on organizing and consolidating the collected raw data into a unified and structured dataset. Aggregating involves merging data from different sources, ensuring uniformity, and structuring it in a way that aligns with the requirements of the machine learning model. Think of this as assembling the pieces of a puzzle to create a cohesive picture. The goal is to transform disparate data points into a coherent dataset that can be effectively utilized for analysis, training machine learning models, and generating valuable insights.
Understanding the intricate process and core concept of data collection requires a grasp of fundamental elements. These include data acquisition, data annotation, and enhancement techniques for existing data and ML models. Furthermore, the convergence of ML and data management in data collection marks a significant trend in the integration of big data and AI. It paves the way for new opportunities in data-driven businesses that strive to master this process.
Over the course of history, individuals have manually gathered information. Even in today’s era dominated by technology like ChatGPT, traditional methods persist, with people using paper-based documents and entering numbers and words into Excel files to document events and observations. However, relying on hard copies and manual data input is not only time-consuming and labor-intensive but also susceptible to human error.

Manual methods of data collection for machine learning may still suffice for small-scale operations, but larger enterprises often opt to delegate these monotonous tasks to external entities or, better yet, automate them whenever possible. In this discussion, we will dig deep into the various prevalent technologies aimed at simplifying the process of gathering data.
Application Programming Interface (API) serves as a software intermediary facilitating communication between different programs. Many contemporary platforms expose APIs, either public or private, providing a direct route to their data. Through APIs, your system can autonomously gather the specific content you seek.
In contrast to web scraping, utilizing APIs avoids legal concerns as their establishment requires permission from the data source, which may impose restrictions on request frequency and content types. APIs also prescribe a data format, with JSON files being the most common for modern REST APIs.
Optical Character Recognition (OCR) is a technology designed to identify printed or handwritten text in scanned papers, images, PDFs, and various files, converting it into a machine-readable electronic format. This not only facilitates the quick digitization of hard copies but also enables the extraction of valuable content from diverse documents for further processing.
Advanced systems like ABBYY FineReader PDF and OCR solutions from Google employ machine learning to analyze document layouts and recognize text, irrespective of the language involved. These technologies play a pivotal role in the expansive field of data collection for machine learning applications.
Robotic Process Automation (RPA) stands as a specialized software designed to tackle repetitive and mundane tasks typically performed by humans. RPA bots, among their various capabilities, handle tasks related to data collection. This includes opening emails and attachments, gathering social media statistics, extracting data from specific fields in documents, and reading necessary information from databases and spreadsheets.
However, it’s important to note that traditional RPA tools are effective with structured and semi-structured data. For unstructured data, which constitutes a significant portion, advanced solutions driven by Artificial Intelligence (AI) are required.
Intelligent Document Processing (IDP) seamlessly integrates three key components:
IDP finds application in collecting and refining data from various sources such as insurance claims, medical forms, invoices, agreements, and other documents, significantly reducing the need for extensive human involvement. This makes it an integral part of the broader landscape of data collection for machine learning.
Web scraping stands as an automated technique to gather, filter, and organize data from websites. Typically, web scrapers or bots navigate through multiple web pages, extracting information like prices, product details, and user comments.
It’s crucial to understand that not every instance of web scraping adheres to legal standards. Generally, scraping information from your own website or collecting publicly available data online is permissible, provided it’s not behind a login. However, there are legal measures in place to regulate access, particularly concerning sensitive personal information like names, ID numbers, addresses, contacts, and shopping preferences. Legal provisions originating from the European Union, such as the General Data Protection Regulation (GDPR), pertain to data that might be employed to ascertain the identity of an EU citizen.
Moreover, various online services explicitly prohibit scraping activities. For instance, Airbnb explicitly states its disapproval of any automated means to collect data from its platform. Therefore, it’s crucial to carefully review a website’s terms of use before deploying a web bot.
Data can be captured through web forms, advanced chatbots, and various tools. Besides this, data can also be automatically obtained from sources such as sensors, Internet of Things (IoT) devices, and Point of Sale (POS) systems. Irrespective of the approach, the effectiveness of collecting data for machine learning hinges on possessing a dependable storage infrastructure for the acquired data.
For companies with long-standing data collection practices, acquiring data for machine learning poses minimal challenges. Conversely, in cases where data is insufficient, leveraging reference datasets available online can prove invaluable. Several platforms facilitate data discovery and sharing, ranging from collaborative analysis tools like DataHub to web-based platforms such as Google Fusion Tables, CKAN, Quandl, DataMarket, and Kaggle. Additionally, specialized systems like Google Data Search and WebTables provide efficient data retrieval options.

The data collection process involves evaluating and shaping the acquired dataset to align with specific project requirements. While leveraging reference datasets, it’s essential to ensure compatibility in format and structure to facilitate seamless integration.
In instances where the obtained dataset falls short, data augmentation techniques play a crucial role in expanding the sample size and enriching the dataset. Techniques like deriving latent semantics, entity augmentation, and data integration contribute to the comprehensive data augmentation process.
Furthermore, integrating external data sources into the existing dataset enhances its richness and diversity. This approach contributes to the overall robustness of the machine learning model. Understanding the complexities of data augmentation techniques is crucial. It enables the development of a well-rounded and comprehensive dataset conducive to successful machine learning outcomes.
Manual or automated creation of a machine learning dataset becomes necessary if suitable datasets for training are unavailable. Manual collection through crowdsourcing platforms like Amazon Mechanical Turk proves indispensable. It facilitates the compilation of relevant data segments to construct the desired dataset.
In cases where image datasets are abundant but textual datasets are insufficient, the use of synthetic data generators is crucial. Employing Generative Adversarial Networks (GANs) proves to be an effective solution in this scenario.
Understanding the underlying principles governing the construction of machine learning datasets is crucial. It is essential for the successful application of synthetic data generators. With a comprehensive dataset in hand, the stage is set for the commencement of the actual machine learning process.
With the necessary data at our disposal, the next step is to embark on the actual machine learning process. This involves extracting meaningful insights from the data and making it comprehensible for an ML model. A crucial aspect of this stage is preparing data for machine learning. This encompasses enhancing existing data to ensure the model generates accurate and reliable results.
The following steps bring us closer to the process of creating a dataset (i.e., classification dataset) for a machine learning model and preparing it for further training, evaluation, and testing.
Irrespective of the data source, the dataset needs thorough cleanup, refining, and completion to ensure it provides relevant insights for the development of an ML system. Data preprocessing is a comprehensive procedure encompassing various crucial tasks, including data formatting and the creation of essential features. Let’s delve deeper into each of these vital processes.

In the practical world, data seldom arrives in a pre-cleaned and preformatted state for immediate processing. As a result, data from diverse sources needs careful formatting. Text data typically appears in the form of an XLS/CSV file or an exported spreadsheet from a database. Similarly, when handling image data, organizing it into catalogs simplifies the process for various ML frameworks.
Although the formatted data can be used for further training, it is susceptible to errors, outliers, and misalignments. The accuracy and precision of the data significantly influence the final outcomes. This underscores the importance of data cleaning or cleansing, which involves both manual and automated techniques to eliminate incorrectly added or categorized data. Furthermore, data cleaning addresses issues such as missing data, duplicates, structural errors, and outliers. This ensures the development of a robust and reliable dataset for various machine learning endeavors.
The intricate process of feature engineering involves handling categorical data, scaling features, and reducing dimensionality. Implementing filter, wrapper, and embedded methods aids in creating additional features that augment the model’s performance. This stage encompasses various processes, including discretization, feature scaling, and data mapping, contributing to the development of impactful features.
Pro Advice: Prioritize Feature Quality
Emphasizing feature quality over quantity significantly impacts the effectiveness of machine learning model development.
Data preparation for machine learning extends beyond preprocessing and involves the crucial task of data labeling. Training a robust ML algorithm necessitates a substantial amount of accurately labeled data. Each dataset requires specific labels, tailored to the unique task at hand.
We live in an era of big data and fierce competition, where data annotation becomes a vital link enabling machines to emulate human activities. While this process may be bypassed when the algorithm’s full functionality isn’t required, the demand for precise data labeling continues to rise. Many companies opt for data annotation partners due to the time-consuming and labor-intensive nature of this process.

In this section, we’ve compiled a set of indispensable strategies to enhance the efficiency and effectiveness of your data collection process. While some of these strategies may echo points discussed earlier, their significance often becomes obscured amidst the influx of information.

Enlisting a proficient team to oversee the intricacies of the data collection process is paramount. Such a team can efficiently manage the flow of data, troubleshoot any issues that may arise, and offer guidance and training to new team members. Regular evaluations and check-ins ensure that all team members are aligned with the overarching objectives.
Translating theoretical discussions into a comprehensive plan is crucial for ensuring a structured and goal-oriented approach to data collection. This plan should delineate the specific responsibilities of team members, outline the requisite data criteria, identify pertinent data sources, detail the tools and methodologies to be employed, and specify the protocols for data storage. Moreover, the plan should encompass a clear timeline that reflects the dynamic nature of the data being collected.
The integrity of the collected data is the bedrock of a successful data collection process. Establishing rigorous protocols for data verification, deduplication, and the implementation of robust backup mechanisms is essential. Regular validation of the collected data is crucial to ensure its accuracy and reliability. This entails confirming its attributability, legibility, contemporaneousness, originality, and accuracy, all of which collectively contribute to data robustness and authenticity.
Amidst the evolving landscape of data protection regulations, it is imperative to ensure stringent adherence to privacy standards and data security protocols. Data collection efforts must comply with relevant regulations, such as GDPR and CCPA, necessitating transparent data usage practices and the prioritization of user privacy. Anonymizing personal data wherever possible and minimizing the collection of unnecessary information are crucial steps toward safeguarding user privacy and upholding ethical data handling practices.
Instituting a robust and comprehensive framework for data governance is indispensable for promoting consistency and coherence across all data collection endeavors within the organization. This framework should encompass detailed guidelines and standardized best practices that govern data handling, storage, and access. An emphasis on uniformity in approach and adherence to ethical and legal guidelines can significantly streamline the data collection process and ensure adherence to industry-specific norms and practices.
Armed with this knowledge, you’re well-equipped to handle data preparation for your specific machine learning project. Alternatively, entrust us with your data, and we’ll efficiently handle the annotation and other tedious tasks, saving you time and costs.

Share the details of your project – like scope, timeframe, or business challenges. Our team will carefully review them and get back to you with the next steps!
© 2026 | All Right Revered.
Subheading : See how we achieved measurable results.
This guide is your roadmap to success! We’ll walk you, step-by-step, through the process of transforming your vision into a project with a clear purpose, target audience, and winning features.