© 2026 | All Right Revered.
Compare and contrast RAG and fine-tuning to enhance your understanding of large language models (LLMs).

Chief Technology Officer
A tech builder, mastering engineering processes and venture building by creating rapid, scalable, and solid product solutions. A staunch advocate for the disruptive capabilities of AI Co-Pilots in the software service industry.

As the realm of Large Language Models (LLMs) continues to evolve, developers and organizations find themselves immersed in a sea of possibilities. These powerful models hold immense potential for various applications, but what happens when the out-of-the-box LLMs don’t quite meet our expectations?
This leads us to a pivotal question: How can we elevate the performance of LLM applications?
Should we turn to Retrieval-Augmented Generation (RAG) or opt for fine-tuning to unlock their full potential?
Before delving deeper into this conundrum, it’s crucial to demystify these two techniques:
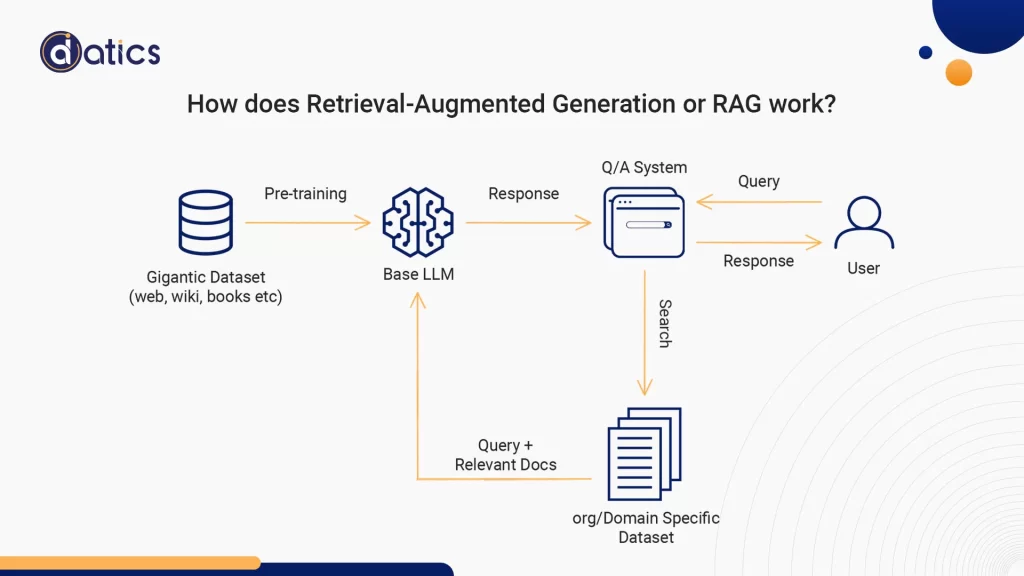
RAG or Retrieval-Augmented Generation combines information retrieval with text generation. It features a retriever system that fetches pertinent document snippets from an extensive database and an LLM that crafts responses using this newfound information. Essentially, RAG empowers the model to “look up” external data, enriching its responses.
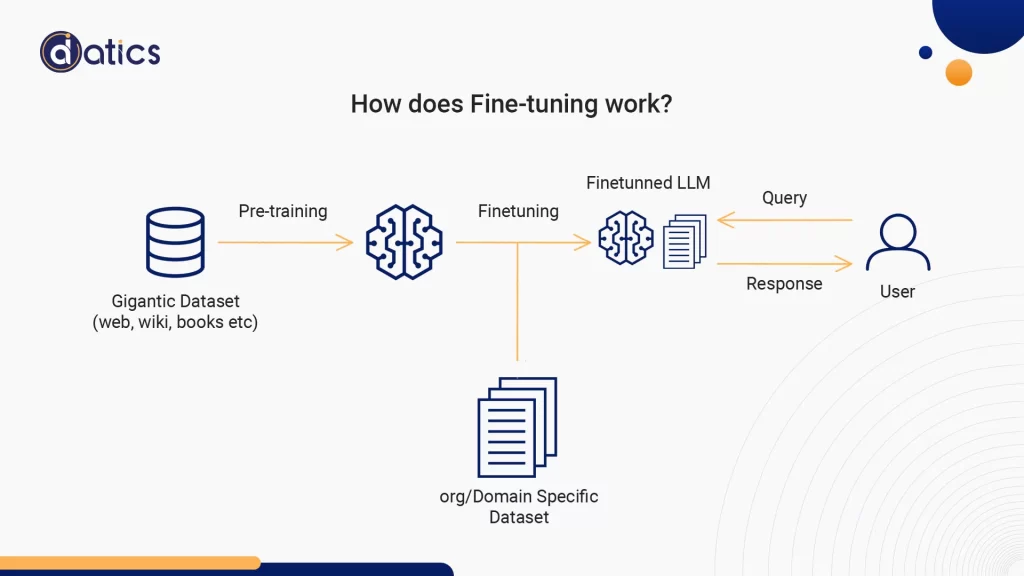
Fine-tuning involves taking a pre-trained LLM and honing it with specific data to tailor it for a particular task or enhance its performance. Fine-tuning adjusts the model’s internal weights based on the provided data, making it more aligned with the unique requirements of the application.
Both RAG and fine-tuning are formidable tools for optimizing LLM-based applications, but they tackle distinct aspects of the enhancement process. This distinction is crucial when determining which path to take.
In the past, the prevailing advice leaned towards experimenting with RAG before delving into fine-tuning. The notion was that both approaches yielded similar results but varied in terms of complexity, cost, and quality.
However, the perspective has evolved. It’s an oversimplification to view RAG and fine-tuning as interchangeable; they are fundamentally different and cater to different facets of LLM applications.
To illustrate this, consider a simple real-world analogy: “Should I take the bus or airplane?” The logical follow-up question is “Where are you going?” These mediums aren’t interchangeable, and the choice depends on the specific context.
In this blog post, we will explore the aspects that set RAG and fine-tuning apart across various dimensions. We will delve into popular use cases for LLM applications and use these dimensions to determine which technique best suits each scenario.
Additionally, we will briefly touch on other crucial factors to consider when developing LLM applications.
The selection of the most suitable technique for adapting large language models (LLMs) can exert a profound influence on the triumph of your Natural Language Processing (NLP) applications. A misguided approach can result in a host of challenges, which include:
An incorrect choice can lead to lackluster model performance for your specific task, giving rise to incorrect outputs that fail to meet your expectations.
If the chosen technique isn’t optimized for your use case, it can give rise to expenses in terms of both model training and inference, burdening your computational resources.
An unsuitable technique might demand additional development and iteration time, forcing you to pivot to a different approach later in the process.
This situation can create delays in deploying your application and making it accessible to users, potentially affecting your project timeline.
Overly intricate adaptation approaches can slow down model interpretability, making it difficult to understand the rationale behind the model’s decisions.
Large and computationally demanding models may pose difficulties when it comes to deploying them in a production environment due to size and resource constraints.
The distinctions between Retrieval-Augmented Generation (RAG) and fine-tuning encompass various facets, such as model architecture, data prerequisites, computational intricacies, and more. Overlooking these complexities can negatively impact your project's timeline and budget
The purpose of this blog post is to prevent futile efforts by precisely explaining when each technique holds the upper hand. With a clear understanding, you can embark on your project with the most appropriate adaptation approach right from the beginning.
Our comprehensive comparison will empower you to make an optimal technological choice that aligns with your business objectives and AI aspirations. This guide to selecting the right tool for the job will serve as the cornerstone of success for your project.
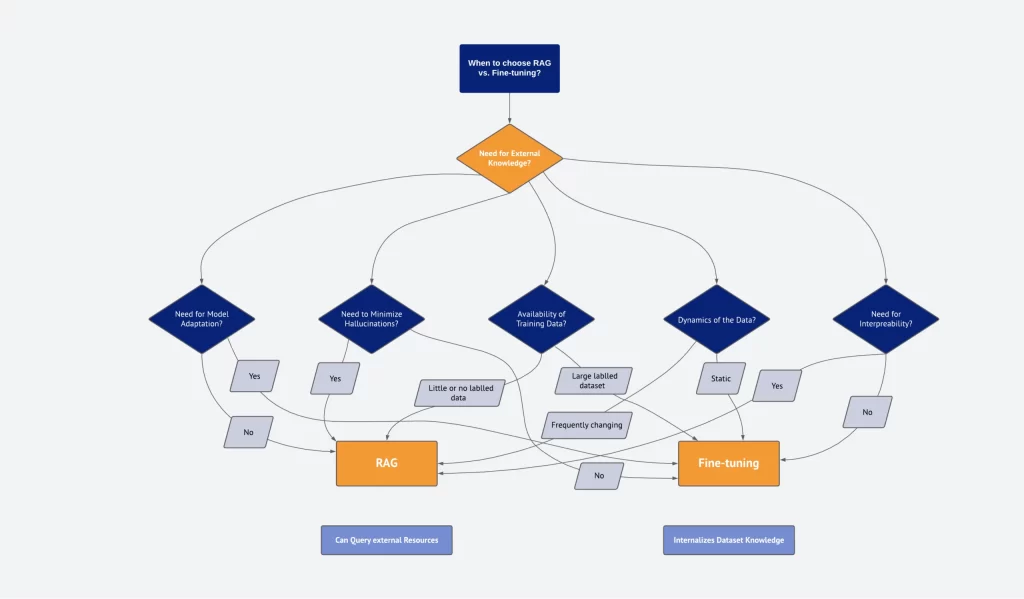
Before deciding between RAG and Fine-tuning, it’s crucial to evaluate the requirements of your Large Language Model (LLM) project from various perspectives and ask some key questions.
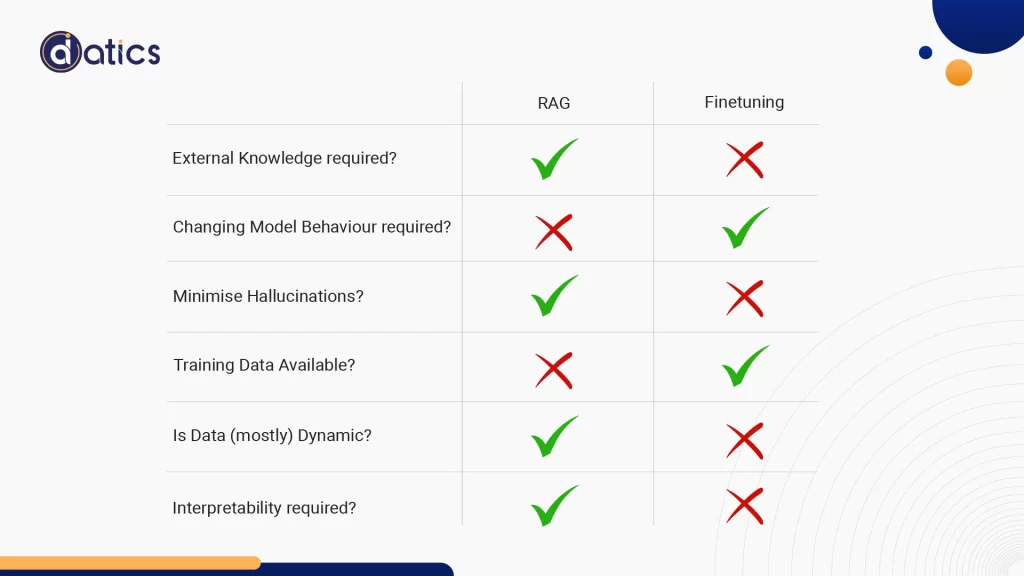
One critical factor to weigh when choosing between Fine-tuning and RAG is whether your application needs access to external data sources. If the answer is yes, RAG typically emerges as the superior choice.
RAG systems are expressly designed to enhance an LLM’s capabilities by fetching pertinent information from knowledge sources before generating a response. This makes RAG particularly well-suited for applications that demand querying databases, documents, or other structured/unstructured data repositories. The retriever and generator components can be fine-tuned to make the most of these external sources.
On the contrary, although it’s feasible to fine-tune an LLM to absorb some external knowledge, it demands a sizable labeled dataset containing question-answer pairs from the target domain. This dataset must be regularly updated to keep up with changes in the underlying data, which can be impractical for frequently changing data sources. Additionally, the fine-tuning process doesn’t explicitly model the retrieval and reasoning steps involved in querying external knowledge.
To sum it up, employing a RAG system is likely to be more effective and scalable than relying solely on fine-tuning when your application depends on leveraging external data sources.
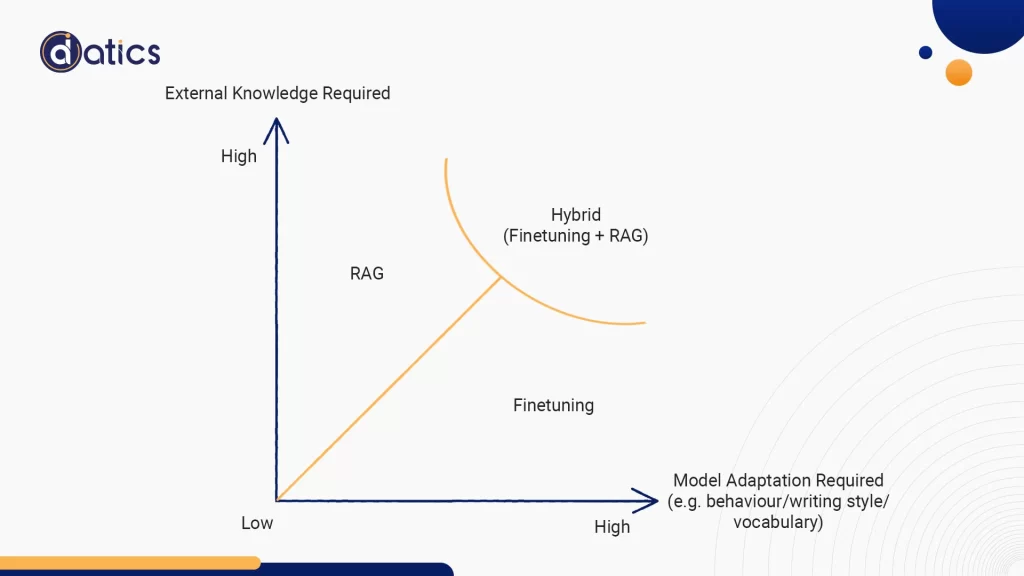
Another crucial factor to take into account is how much you need the model to adjust its behavior, writing style, or customize its responses for domain-specific applications.
Fine-tuning stands out due to its ability to tailor an LLM’s behavior to address particular nuances, tones, or terminologies. Whether you desire the model to mimic a medical professional, adopt a poetic writing style, or employ industry-specific jargon, fine-tuning with domain-specific data provides you with the means to achieve these customizations.
This capacity to shape the model’s behavior becomes invaluable for applications where aligning with a specific style or domain expertise is of utmost significance.
On the contrary, RAG, while proficient in integrating external knowledge, places its primary emphasis on information retrieval and lacks inherent adaptation of its linguistic style or domain specificity based on retrieved information. While it can extract pertinent content from external data sources, it may not demonstrate the customized nuances or domain expertise that a fine-tuned model can provide.
Hence, for applications demanding specialized writing styles or profound alignment with domain-specific vocabulary and conventions, fine-tuning offers a clearer route to attain such alignment. It furnishes the depth and customization essential for creating content that truly connects with a specific audience or domain of expertise, ensuring the authenticity and well-informed nature of the generated output.
Recapping the primary considerations for choosing between RAG and finetuning, we find that they are, in essence, distinct and can even be employed separately or in collaboration for specific use cases. However, before delving into practical applications, there are several more crucial aspects to evaluate:
One significant drawback of large language models is their proneness to generate false or imaginative information, often referred to as “hallucinations.” These fabrications can pose a problem in applications where accuracy and truthfulness are crucial.
Although fine-tuning can partially minimize hallucinations by anchoring the model in domain-specific data, it can still generate inaccurate responses when encountering unfamiliar inputs. This requires frequent retraining on new data to reduce such fabrications.
On the contrary, RAG systems, with their inherent resistance to hallucinations, employ a two-step fact-checking process. Initially, the retriever finds relevant facts from external knowledge sources, after which the generator formulates a response grounded in this evidence. This methodology lowers the model’s tendency to produce inaccurate information.
Consequently, in scenarios where the imperative is to filter out inaccurate or imaginative content, RAG systems furnish pre-established mechanisms ensuring accuracy and truthfulness.
When choosing between RAG and finetuning, the quantity and quality of domain-specific labeled training data play a pivotal role.
The effectiveness of fine-tuning an LLM for specific tasks or domains heavily relies on the quality and quantity of available labeled data. A comprehensive dataset enables the model to gain profound insights into the peculiarities, complexities, and distinctive patterns of a particular domain, thereby enhancing its ability to generate precise and contextually appropriate responses.
Conversely, when dealing with limited data, the enhancements resulting from fine-tuning may be minimal. In certain instances, a limited dataset could even result in overfitting, where the model excels with the training data but performs poorly when encountering unseen or real-world inputs.
On the other hand, RAG systems are less dependent on training data as they leverage external knowledge sources. Even with limited labeled data, RAG can perform competently by incorporating insights from external sources. The combination of retrieval and generation ensures that the system remains informed, even in data-scarce scenarios.
Essentially, when abundant labeled data describing the domain’s nuances is available, fine-tuning can provide a more customized and polished model behavior. However, in situations where such data is scarce, a RAG system serves as a robust alternative, guaranteeing that the application remains well-informed by data and contextually aware thanks to its retrieval capabilities.
Assessing the dynamic nature of data becomes a critical factor when deciding between RAG and fine-tuning. How frequently the data undergoes updates and the model’s need to stay current are central considerations.
Fine-tuning an LLM on a specific dataset results in the model’s knowledge being essentially frozen at the time of training. Frequent data updates, alterations, or expansions can quickly render the model outdated. To keep the LLM relevant in dynamic environments, frequent retraining becomes imperative. This process, however, is both time and resource-intensive, requiring careful monitoring to ensure the updated model maintains its effectiveness across diverse scenarios and avoids the development of new biases or knowledge gaps.
On the contrary, RAG systems hold a distinct advantage in dynamic data settings. Their retrieval mechanism consistently queries external sources, ensuring that the information used to generate responses remains up-to-date. As external knowledge bases or databases evolve, the RAG system seamlessly incorporates these changes, preserving its relevance without the need for frequent model retraining.
In short, when dealing with a swiftly changing data set, RAG demonstrates an agility that conventional fine-tuning struggles to match. By maintaining a continuous connection to the most current data, RAG guarantees that the generated responses align with the present state of information, establishing itself as the preferred choice for dynamic data scenarios.
In assessing the suitability of your LLM application, the extent of transparency becomes a crucial factor to ponder.
Fine-tuning, while a potent tool, often operates like a mysterious black box, obscuring the rationale behind its responses. As the model retrieves data from its training set, understanding the exact source or logic behind each response becomes increasingly challenging. This opacity can pose trust issues for both developers and users, particularly in applications where comprehending the “why” behind an answer holds paramount significance.
In contrast, RAG systems provide a level of transparency not typically associated with solely fine-tuned models. Thanks to the two-step nature of RAG—retrieval followed by generation—users gain visibility into the process. The retrieval phase allows for scrutiny of the selection process for external documents or data points, creating a tangible trail of evidence that can be assessed to comprehend the basis of a response.
This ability to trace a model’s answer back to specific data sources proves invaluable in applications requiring a high degree of accountability or when the accuracy of generated content needs validation.
In essence, if prioritizing transparency and the capacity to interpret a model’s responses stands as a key concern, RAG emerges as the superior choice. By dissecting response generation into discrete stages and facilitating insight into its data retrieval, RAG nurtures a stronger sense of trust and comprehension in its outputs.
Making the choice between RAG and fine-tuning becomes a more easy choice when taking these aspects into account. If our objective leans toward tapping into external knowledge sources while also prioritizing transparency, then RAG is the obvious choice. Conversely, if we find ourselves with a stable set of labeled data and aim to tailor the model closely to specific requirements, then fine-tuning emerges as the superior option.
Customer support chatbots often rely on external knowledge sources, including product information, FAQs, and customer records. The effectiveness of these chatbots hinges on their ability to access and retrieve pertinent information from these sources to assist customers.
Depending on the organization and industry, chatbots may need to adapt their responses to align with specific terminologies, tones, or industry conventions. This adaptation ensures that chatbots can communicate effectively within the context of the specific industry they serve.
Customer support chatbots often rely on external knowledge sources, including product information, FAQs, and customer records. The effectiveness of these chatbots hinges on their ability to access and retrieve pertinent information from these sources to assist customers.
In customer support, providing incorrect or misleading information can harm the customer experience. Therefore, minimizing the occurrence of hallucinations, where the chatbot generates inaccurate responses, is essential.
Consider whether the organization possesses a structured and labeled dataset of past customer interactions and support queries that can be used for training the chatbot. Evaluate the quantity and suitability of this training data.
Customer support data is often dynamic, with frequent updates related to product changes, policies, and customer inquiries. Assess how frequently this data changes and the importance of keeping the chatbot up-to-date with these changes.
Consider whether the organization possesses a structured and labeled dataset of past customer interactions and support queries that can be used for training the chatbot. Evaluate the quantity and suitability of this training data.
In customer support scenarios, understanding why the chatbot provided a particular response can be crucial for both customers and support agents. Determine whether there is a need for transparency in how the chatbot generates its answers, especially in situations where trust and accountability are paramount.
For chatbots used in customer support, a RAG system could be a suitable choice, especially when dealing with dynamic data and the need for transparency. RAG’s ability to retrieve external knowledge can enhance the chatbot’s responses.
However, it’s essential to strike a balance between external knowledge access and domain-specific adaptation. Depending on the specific requirements, a combination of RAG and fine-tuning may be considered to provide accurate, up-to-date, and contextually relevant support.

Legal document analysis often demands access to external legal databases, case law, and regulations to provide accurate interpretations and advice. The system’s effectiveness relies on its ability to tap into and retrieve relevant information from these sources to analyze legal documents.
Depending on the specific legal domain (e.g., corporate law, intellectual property, criminal law), the system may need to adapt its responses to legal terminologies and specific nuances. Customization to align with the linguistic style and domain expertise of the legal field it serves may be essential.
In the legal domain, providing incorrect information or misinterpreting legal texts can have severe consequences. Minimizing the risk of hallucinations and ensuring the system delivers accurate legal insights is crucial.
Legal document analysis benefits from structured and labeled datasets of legal documents and historical case law. The availability of such data can influence the choice between RAG and fine-tuning.
Legal documents and regulations can undergo frequent updates and changes. Consider how dynamic the legal data is and whether the system needs to provide real-time legal analyses.
In legal applications, stakeholders often require transparency and the ability to interpret the system’s reasoning behind its legal analyses. Consider the need for traceability and validation of legal insights.
For legal document analysis, a RAG system may be well-suited, especially when dealing with dynamic legal data sources and the need for transparency. However, if the legal domain requires extensive adaptation to specific terminologies or linguistic styles, fine-tuning could be considered in conjunction with RAG to strike a balance between external knowledge access and domain-specific adaptation.
A content recommendation system for media streaming platforms relies on external knowledge sources to suggest relevant movies or TV shows to users. These recommendations often consider factors such as user preferences, viewing history, and content metadata. The recommendation system needs access to external data sources to provide accurate and personalized content suggestions.
Depending on the streaming platform’s audience and content library, the recommendation system may require the ability to adapt its recommendations to specific genres, languages, or cultural preferences. It needs to tailor its content suggestions based on these factors.
In content recommendation, providing irrelevant or inaccurate suggestions can lead to user dissatisfaction. It is crucial to minimize the risk of the recommendation system suggesting content that doesn’t align with users’ preferences or the platform’s content catalog.
Consider whether the streaming platform has access to historical user interactions, ratings, and content metadata. This data can be valuable for training the recommendation system. Assess the quality and quantity of available training data.
Media streaming platforms constantly update their content libraries, adding new titles, removing old ones, and adjusting recommendations based on user feedback. The content catalog changes frequently, and it’s important for the recommendation system to adapt to these changes in real-time.
Users often appreciate transparency in content recommendations to understand why a particular movie or show was suggested. The recommendation system needs to provide explanations for its suggestions, and interpretability is important for user trust.
For a content recommendation system in a media streaming platform, a combination of RAG and fine-tuning may offer the best results. RAG can be used to access external knowledge sources, such as content metadata and user preferences, to enhance recommendations.
Fine-tuning can help adapt the model to specific genres, languages, or cultural contexts. Additionally, fine-tuning can provide interpretability, allowing users to understand why certain content was recommended.
Regular model updates based on changing content catalogs can ensure the system remains up-to-date and aligned with user preferences.
In addition to the primary factors discussed earlier, several other dimensions merit consideration when determining the suitability of RAG, fine-tuning, or a combination of both for your LLM application:
How well can your chosen method scale as your organization grows and your data requirements evolve?
RAG systems, with their modular design, often provide a more straightforward path to scalability, especially when dealing with expanding knowledge bases. In contrast, fine-tuning a model for accommodating larger datasets can impose significant computational demands.
Does your application demand real-time or near-real-time responses?
Evaluate the latency introduced by each method. RAG systems, involving data retrieval before generating responses, may introduce more latency compared to fine-tuned LLMs, which generate responses based on internal knowledge.
Assess the robustness of each method to various types of inputs. While RAG systems can leverage external knowledge sources and handle a wide range of questions, well-fine-tuned models may offer more consistency in specific domains.
Be mindful of ethical and privacy considerations. Storing and retrieving data from external databases may raise privacy concerns, particularly if the data is sensitive. Fine-tuned models, while not directly querying live databases, can produce outputs based on potentially sensitive training data.
Consider the compatibility of RAG or fine-tuning with your existing infrastructure, whether it involves databases, cloud platforms, or user interfaces. Integration ease can influence your choice.
Factor in the needs and preferences of end-users. Do they require detailed, reference-backed answers (favoring RAG), or do they prioritize speed and domain-specific expertise (favoring fine-tuning)?
Evaluate the cost implications of each method. Fine-tuning, especially for large models, can be expensive, but recent advances in parameter-efficient techniques may mitigate costs. RAG setup can involve substantial initial investments, including integration and potential licensing fees, with ongoing maintenance costs.
Acknowledge the complexity of implementation. Fine-tuning can become intricate as you manage model versions and ensure performance across various scenarios. RAG systems, too, can be complex, involving multiple components and the upkeep of databases to ensure seamless operation.
Choosing between RAG and fine-tuning demands a nuanced assessment of your LLM application’s unique requirements and priorities. There is no universal solution; success hinges on aligning the optimization method with the specific task at hand.
By thoroughly evaluating key criteria—such as the need for external data, model adaptation, training data availability, data dynamics, result transparency, and more—organizations can make informed decisions on the optimal approach. In some instances, a hybrid approach, combining RAG and fine-tuning, may offer the best results.
Avoid making assumptions about one method’s universal superiority. These tools are versatile but must align with your objectives to unleash their full potential. Misalignment can hinder progress, while the right choice accelerates it.
As your organization explores ways to enhance LLM applications, resist oversimplification, view RAG and fine-tuning as complementary tools, and select the method that empowers your model to fulfill its capabilities in harmony with your specific use case. The possibilities are immense, but realizing them requires strategic execution. The tools are ready—now, let’s harness their power.
In conclusion, the Chief Technology Officer (CTO) is an ever-evolving role that mirrors the dynamic nature of the tech industry itself. As we move forward into a future characterized by AI, human-centric design, ethical considerations, and complex technological convergence, CTOs will continue to play a pivotal role in shaping the trajectory of organizations.
Embracing these challenges and staying at the forefront of technological advancements are paramount for CTOs looking to drive innovation, enhance business value, and champion the user experience. The CTO’s journey is one of adaptability, leadership, and a commitment to bridging the gap between technology and business to create a brighter technological future for all.

Share the details of your project – like scope, timeframe, or business challenges. Our team will carefully review them and get back to you with the next steps!
© 2026 | All Right Revered.
Subheading : See how we achieved measurable results.
This guide is your roadmap to success! We’ll walk you, step-by-step, through the process of transforming your vision into a project with a clear purpose, target audience, and winning features.